11 марта мы побывали на Kyiv Data Spring – крупнейшей конференции про Data Science и Machine Learning в Восточной Европе.

Сама тема для нас не новая, но было интересно услышать про опыт других людей и выводы, которые они сделали. В связи с чем нам хотелось бы кратко пройтись по всей этой теме от “что это такое” до “что нас ждет в будущем”.
Вот так выглядит классическая схема, которая примерно иллюстрирует чем же занимается Data Science.
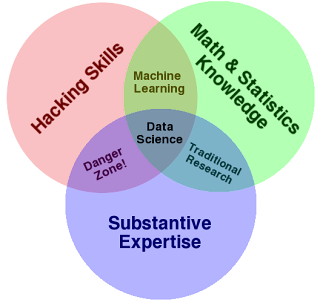
Навыки программирования, математики и статистики, а также понимание бизнеса и его проблем – вот что определяет необходимый набор компетенций специалиста в этой области. Задача Data Science заключается в анализе имеющихся и сборе новых данных. Результатами такого анализа могут быть понятные для заказчика рекомендации к действию или программные решения для прогнозирования результатов и классификации новых данных.
Уже давно как идет тренд внедрения Data Science в той или иной форме в компаниях, которые желают выстоять проверку временем и остаться актуальными спустя, как прогнозируют, 10-20 лет. В некоторых IT компаниях уже давно как открыты школы и курсы по этой теме, наравне с привычными нам подготовительными программами для разработчиков и тестировщиков. Почему это важно? Да потому что в будущем более качественный сервис, основанный на Data Science, будет вне конкуренции, а остальные просто выпадут из рынка.
Если вас заинтересует эта тема, то информации сегодня достаточно. К примеру, можно взять за основу бесплатный знаменитый курс на Coursera: Machine Learning – Stanford University. Также, важную роль играет замечательное сообщество вокруг сервиса Kaggle, где не только можно заработать на соревнованиях по Data Science, но и получить советы и прикоснуться к опыту других. А еще можно заняться исследованиями различных проблем человечества 😉 Этот сервис позволит вам поработать с реальными вопросами, а не вымышленными тестовыми задачами. Ибо в Data Science одна из трех главных компетенций – это познание business domain.
Взявшись за эту тему, будьте готовы к неправильным вопросам и ложным выводам. Часто за поставленным вопросом не видно изначальной проблемы. Возможно, человек интуитивно или сознательно сделал первые шаги декомпозиции и навел вас не на тот путь, откатитесь назад к начальной проблеме – задайте правильный вопрос. А делая выводы пытайтесь не одурачить самих себя. Во-первых, большие погрешности могут быть в самом dataset, который вы анализировали и использовали для обучения. Во-вторых, результаты могут выглядеть как та истина, которую вы и искали, а может оказаться, как это часто бывает, что это просто совпадение. Нашему мозгу привычно искать закономерности и подмечать паттерны. Вот здесь как раз надо приложить знания предметной области, чтобы приблизиться к истине.
Уже сейчас продукты машинного обучения применяются для диагностирования рака кожи и генетических отклонений, прогнозирования спроса и классификации изображений, создания умных городов будущего уже сегодня. Масштабы использования разнятся от ритейлера-гиганта Walmart до частных домов. Ваш газон портят чужие коты – не проблема! Обучите за 3 дня нейронную сеть определять их присутствие по изображению с камер наблюдения, а газонные поливалки сделают свое мокрое дело. И это реальный кейс.
Сейчас, когда все больше и больше процессов поддаются автоматизации, многие задаются вопросам: “Как же выжить, когда придут роботы?”. Андрей Себрант дает ответ:
- лидировать в команде творческих людей и творческих машин
- уметь обучать алгоритмы, а не только людей
- иметь смелость делегировать машине, а не только людям
- отличать что кому делегировать
Подытожим словами Ройа Амера: “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run”.
Так что, даем верные оценки и смотрим в будущее уже сегодня! 😉 Видео записи докладов доступны в канале Kyiv Data Spring.
You are not signed in. Sign in to post comments.